Someone asked me today how to find a duplicate entry in a table. One of his tables became corrupted after SQL Server accidentally dropped his Unique Index constraint on a field. As a result, the same data got inserted multiple times and he needed a way to find out which and how to delete them.
So suppose you have a simple "book" table with two columns ("Id" and "Name") with the following data and "Id" is a primary key and is also identity. "Name" column should have a Unique Index constraint but was lost when the server crashed.
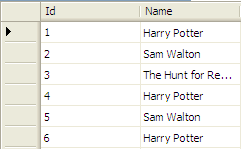
To locate the books with multiple entries, we can group a query like this:
SELECT Name, count(*) FROM book GROUP BY Name HAVING count(*) > 1
When it comes to deleting duplicate data, it's a little more complicated. One way is to create a temporary table, copy rows over to the temp table, truncate your original table and re-insert back from the temp table using the DISTINCT clause. So first thing is to always backup your table before you begin any big deletion. On other databases, you would use CREATE TEMP TABLE syntax and omit the pound (#) sign that SQL Server uses.
-- Create our temp table
CREATE TABLE #temp
(
Id int,
Name varchar(50)
PRIMARY KEY(Id)
)
-- Copy data to a temp table
INSERT INTO #temp SELECT * FROM book
-- Empty the table
TRUNCATE TABLE book
-- Copy unique data back to our original table
INSERT INTO book (Name) SELECT DISTINCT Name FROM #temp
-- Clean up
DROP TABLE #temp
You could have worked the other way around and insert unique data into the temp table by DISTINCT and then re-insert back to original table but I decided to copy all rows first since it will act as a rough backup.
Another way is to use "sp_rename" to copy over the original table and then INSERT INTO a new table again using SELECT DISTINCT. The copy is slightly faster and cleaner since you don't have to create any temporary table. If you're not running SQL Server, you can also use the ALTER TABLE ... RENAME TO ... command instead of sp_rename.
-- Rename table
sp_rename 'book', 'temp_book'
-- Create our table
CREATE TABLE book
(
Id int IDENTITY,
Name varchar(50)
PRIMARY KEY(Id)
)
-- Copy unique rows
INSERT INTO book (Name) SELECT DISTINCT Name FROM temp_book
-- Clean up
DROP TABLE temp_book
There you go, now you know how to deal with duplicate data next time your database crashes on you or you simply forgot to put a unique constraint.